Gemma-4 op de DGX Spark: de prijs van context
Negen benchmarks van Gemma-4-26B-A4B-it op de DGX Spark met llama-benchy en vLLM. Decode houdt stand; prefill en queueing bepalen het gevoel.
Ik wilde weten hoe goed een DGX Spark zich houdt als lokale AI-machine voor een kantooromgeving.
Niet theoretisch. Gewoon: Gemma-4-26B-A4B-it laden in vLLM, llama-benchy ertegenaan, context windows groter maken, output langer, concurrency omhoog, multi-turn erbij, en kijken waar het prettig blijft en waar de wachttijd pijn gaat doen. En toen dat verhaal zich begon af te tekenen kwam er een tweede vraag: wat als ik niet meer in lockstep test, maar verzoeken organisch laat aankomen zoals in een echt kantoor? Daarvoor pakte ik vLLM’s eigen benchmark-suite erbij, die wel doet wat llama-benchy niet doet: Poisson-aankomsten, percentielen, echte conversation-data. Hoe ik dit allemaal meet staat in de methodologie.
De korte versie: voor normaal kantoorgebruik ziet dit er goed uit. Korte tot middelgrote prompts, langere outputs, en zelfs gesprekken over meerdere beurten blijven snel aanvoelen, ook met tien gebruikers tegelijk. Bij grote context windows wordt niet tokens per seconde het probleem, maar hoe lang iemand naar een leeg chatvenster kijkt voordat de eerste token komt. En als je de machine echt overbelast, schaalt ‘ie niet, hij queue’t.
Dat maakt dit geen “kan de DGX Spark het wel of niet”-verhaal. Het maakt het een workload-verhaal. Negen tests, twee methodes, één machine. Het is een van de build-logs onder de gids LLMs draaien op de DGX Spark.
Waarom deze test
Bij on-prem AI praat je al snel over privacy, data dichterbij houden en minder afhankelijk zijn van hosted modellen. Dat klopt allemaal, maar uiteindelijk komt er een plattere vraag achteraan.
Kan de machine het aan?
Een lokaal model dat één demo-prompt netjes beantwoordt is leuk. Maar productie lijkt daar zelden op. Daar heb je meerdere gebruikers, grotere context, agent-flows, tool-calls, retries en soms iemand die een halve roman in een ticket plakt.
Daarom wilde ik niet alleen tokens per seconde meten bij één prompt. Ik wilde zien wat er gebeurt als je de machine vanuit verschillende hoeken belast: van “tien gebruikers, korte prompts, lange antwoorden” tot “tien gebruikers, gesprekken van vijf beurten, groeiend geheugen” tot “verzoeken die organisch aankomen zoals in een echt kantoor, niet allemaal tegelijk en niet allemaal hetzelfde formaat”.
Voor deze benchmarks testte ik één model:
google/gemma-4-26B-A4B-it- BF16
- DGX Spark, NVIDIA GB10, 128 GB unified memory
- vLLM als OpenAI-compatible endpoint
Dense komt later. MoE vs dense ook. Dit stuk gaat alleen over Gemma-4-26B-A4B-it op de DGX Spark. Deze run draait op BF16; wat er met dezelfde Gemma-4 gebeurt als je naar NVFP4 quantiseert is een apart verhaal.
De verwachting vooraf
Mijn verwachting was simpel: MoE zou redelijk goed blijven bij concurrent requests, maar ik dacht dat de DGX Spark sneller tegen zijn grenzen zou lopen zodra de context groot werd.
Vooral bij 25k context.
Context is duur. Je betaalt niet alleen voor de prompt die binnenkomt, maar ook voor de KV-cache die vLLM moet bijhouden. Als je dat vermenigvuldigt met meerdere gebruikers, wordt het ineens een geheugenvraagstuk én een wachtrijvraagstuk.
Ik was benieuwd naar vijf dingen:
- blijft decode nog bruikbaar als context groeit?
- hoeveel doet prefill met de tijd tot de eerste token?
- wat gebeurt er als de prompt kort is, maar de output lang?
- hoe gedraagt het zich bij multi-turn gesprekken, waar context per beurt aandikt?
- en (pas later toegevoegd) hoe ziet dat er allemaal uit als verzoeken niet in lockstep komen, maar organisch?
Die laatste vraag bleek de helft van het verhaal.
De testopstelling
De server draaide in Docker met de officiële vLLM-image:
docker run -d --name vllm-bench \
--gpus all --ipc=host \
-v appliance_hf-cache:/root/.cache/huggingface \
-p 8000:8000 \
vllm/vllm-openai:v0.20.1 \
--model google/gemma-4-26B-A4B-it \
--served-model-name gemma-4-26b-a4b-bf16 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--kv-cache-dtype fp8 \
--limit-mm-per-prompt '{"image":0,"audio":0}' \
--async-scheduling \
--no-enable-prefix-caching \
--host 0.0.0.0 \
--port 8000Een paar details doen ertoe.
Prefix caching staat bewust uit. Ik wilde eerst de rauwe prefill-kosten zien, niet een benchmark die mooier wordt omdat prompts op elkaar lijken.
De KV-cache draait op fp8. Zonder dat wordt 128k context met meerdere requests tegelijk al snel een geheugenoefening waar je weinig aan hebt.
Alle negen tests hieronder gebruiken precies deze server-config. Geen herstart, geen tussentijdse aanpassing. Wat varieert is de workload: prompt-grootte, output-grootte, concurrency, depth, en bij de open-loop tests ook arrival rate en burstiness.
Wat de Spark hiervan maakt:
| Onderdeel | Waarde |
|---|---|
| Model weights (BF16) | ~48 GB |
| KV-cache headroom (fp8) | ~65 GB |
| Theoretisch parallel @ 128k | ~4 requests |
| Theoretisch parallel @ 8k | ~50 requests |
Bij volle context per request is het geheugen krap. In de praktijk gebruikt geen enkele test 128k tegelijk per gebruiker, dus de bottleneck verschuift naar prefill-compute en scheduler-batching. Dat zien we hieronder terug.
Run A: context groter maken
De eerste run liet de context groeien van 4k naar 25k. Concurrency ging mee van 1 naar 5 en 10. Closed-loop, dus N gebruikers in lockstep.
uvx llama-benchy \
--base-url http://localhost:8000/v1 \
--model gemma-4-26b-a4b-bf16 \
--pp 4096 8192 16384 25000 \
--tg 256 \
--depth 0 \
--concurrency 1 5 10 \
--runs 3 \
--latency-mode generation \
--format mdpp is prefill, oftewel hoeveel prompttokens erin gaan. tg is decode, oftewel hoeveel tokens het model daarna genereert. llama-benchy rapporteert mean ± stddev. Geen p95. Dat is belangrijk om te onthouden, want bij latency wil je jezelf anders al snel rijk rekenen.
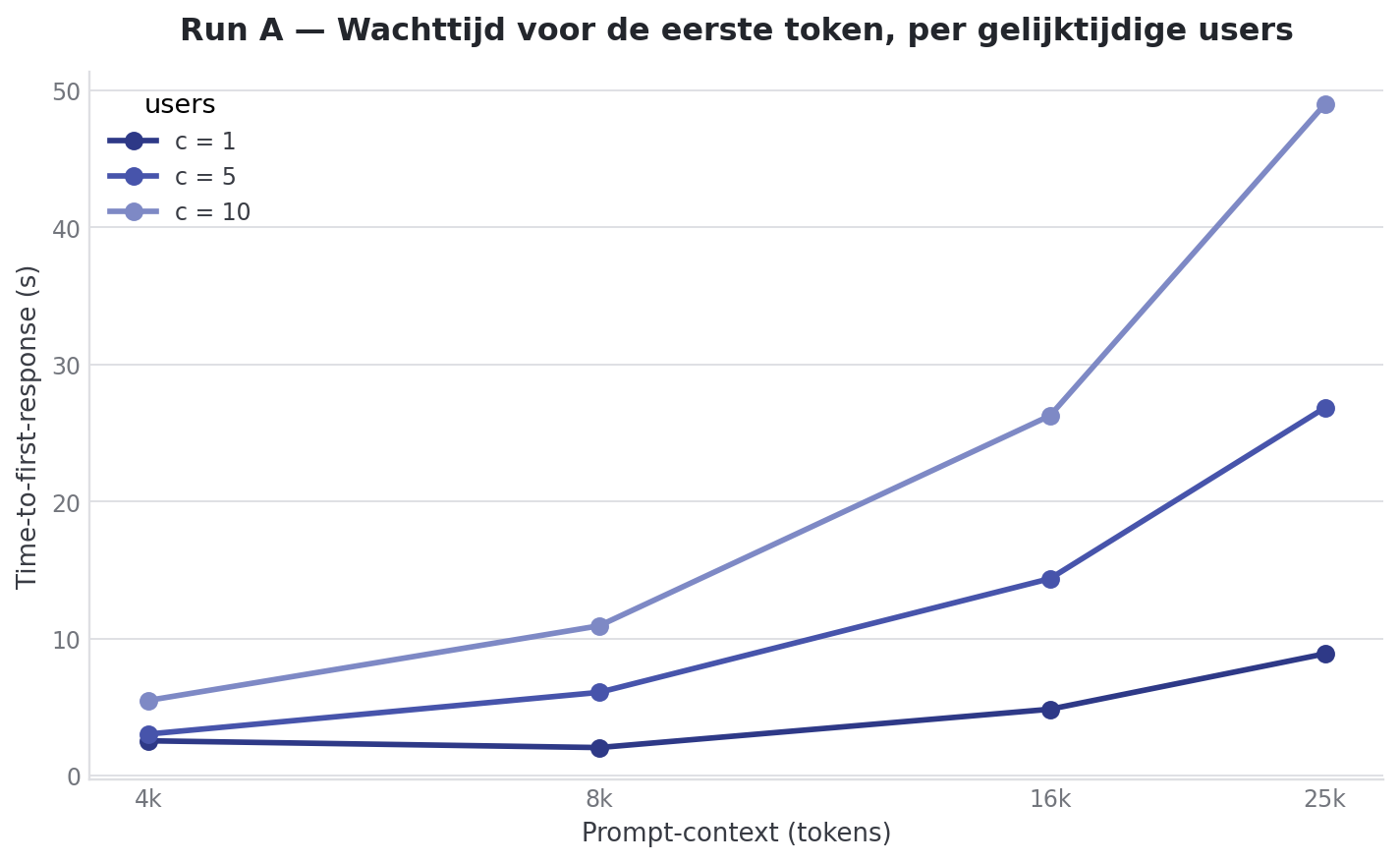
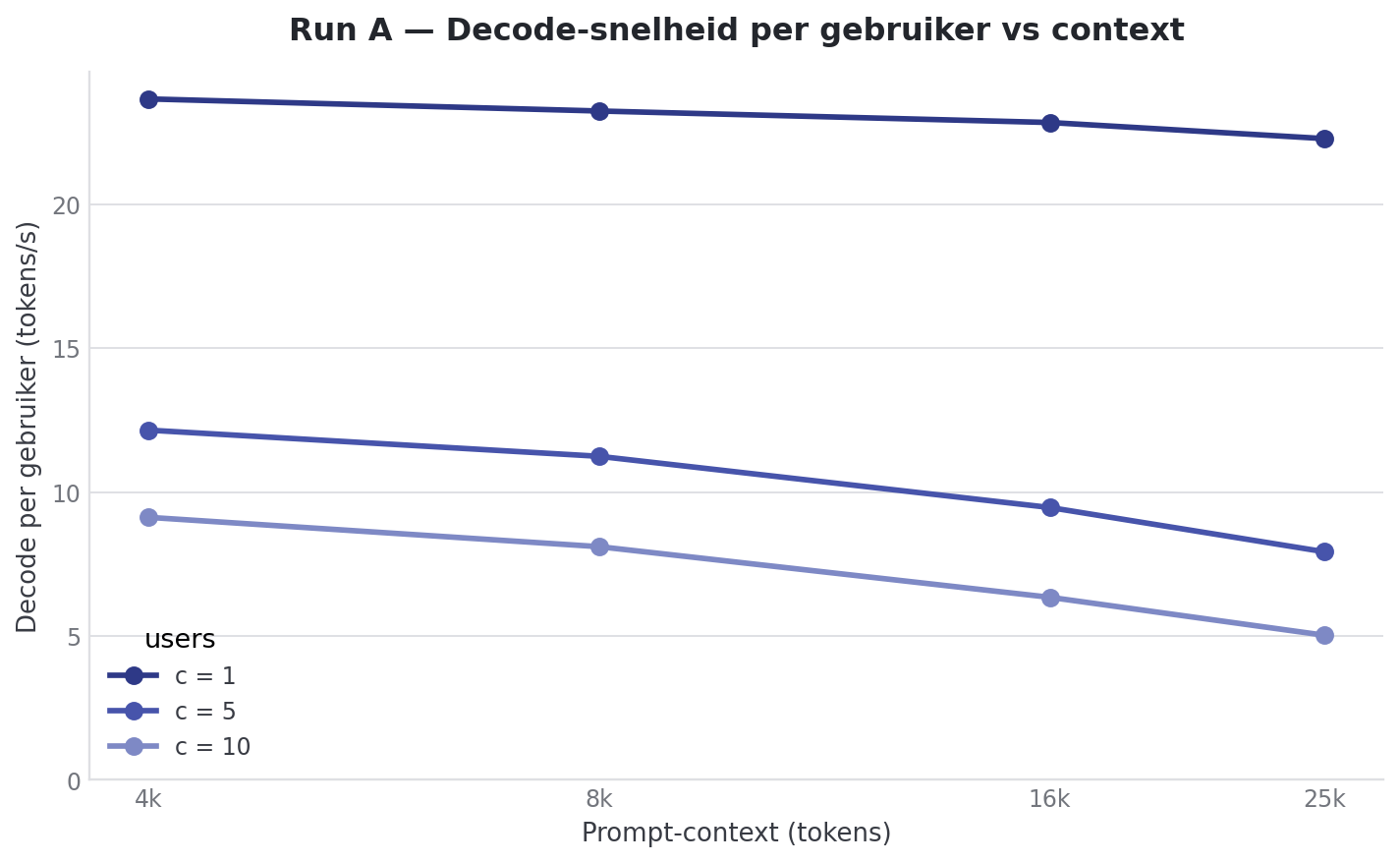
Dit is de samenvatting uit Run A:
| Context | Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|---|
| 4k | 1 | 3677.85 ± 1259.27 tok/s | 24.08 ± 0.02 tok/s | 24.08 ± 0.02 tok/s | 1.37 ± 0.52s |
| 4k | 5 | 5722.96 ± 94.70 tok/s | 12.55 ± 0.49 tok/s | 57.07 ± 2.64 tok/s | 2.29 ± 0.82s |
| 4k | 10 | 5475.53 ± 888.14 tok/s | 9.48 ± 0.73 tok/s | 84.40 ± 3.08 tok/s | 4.46 ± 2.38s |
| 8k | 1 | 6121.87 ± 62.31 tok/s | 23.69 ± 0.02 tok/s | 23.69 ± 0.02 tok/s | 1.39 ± 0.01s |
| 8k | 5 | 5444.57 ± 12.82 tok/s | 11.48 ± 0.92 tok/s | 49.42 ± 1.60 tok/s | 4.34 ± 1.91s |
| 8k | 10 | 5478.98 ± 11.48 tok/s | 8.52 ± 1.10 tok/s | 67.72 ± 0.91 tok/s | 7.99 ± 4.03s |
| 16k | 1 | 4607.64 ± 23.05 tok/s | 23.34 ± 0.05 tok/s | 23.34 ± 0.05 tok/s | 3.42 ± 0.00s |
| 16k | 5 | 4466.35 ± 27.19 tok/s | 10.05 ± 1.75 tok/s | 38.41 ± 0.12 tok/s | 10.43 ± 4.69s |
| 16k | 10 | 4453.92 ± 18.19 tok/s | 6.79 ± 1.62 tok/s | 45.76 ± 0.43 tok/s | 18.92 ± 9.43s |
| 25k | 1 | 3621.25 ± 18.50 tok/s | 22.75 ± 0.08 tok/s | 22.75 ± 0.08 tok/s | 6.39 ± 0.05s |
| 25k | 5 | 3561.78 ± 9.23 tok/s | 8.46 ± 2.36 tok/s | 27.93 ± 0.08 tok/s | 19.63 ± 8.87s |
| 25k | 10 | 3565.35 ± 8.21 tok/s | 5.40 ± 2.00 tok/s | 30.73 ± 0.12 tok/s | 35.67 ± 18.00s |
Run B: 25k context vasthouden, concurrency omhoog
Daarna draaide ik dezelfde 25k-context zwaarder. Niet meer variëren in context, alleen gebruikers erbij.
uvx llama-benchy \
--base-url http://localhost:8000/v1 \
--model gemma-4-26b-a4b-bf16 \
--pp 25000 \
--tg 256 \
--depth 0 \
--concurrency 5 10 20 \
--runs 3 \
--latency-mode generation \
--exit-on-first-fail \
--format mdGeen OOM. Geen crash. De DGX Spark overleefde 20 gelijktijdige requests met 25k context.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 5 | 3559.17 ± 6.72 tok/s | 8.51 ± 2.40 tok/s | 27.88 ± 0.05 tok/s | 19.86 ± 9.00s |
| 10 | 3569.77 ± 2.99 tok/s | 5.37 ± 1.99 tok/s | 30.68 ± 0.09 tok/s | 35.44 ± 17.95s |
| 20 | 3563.64 ± 8.78 tok/s | 3.16 ± 1.41 tok/s | 32.26 ± 0.10 tok/s | 67.37 ± 36.44s |
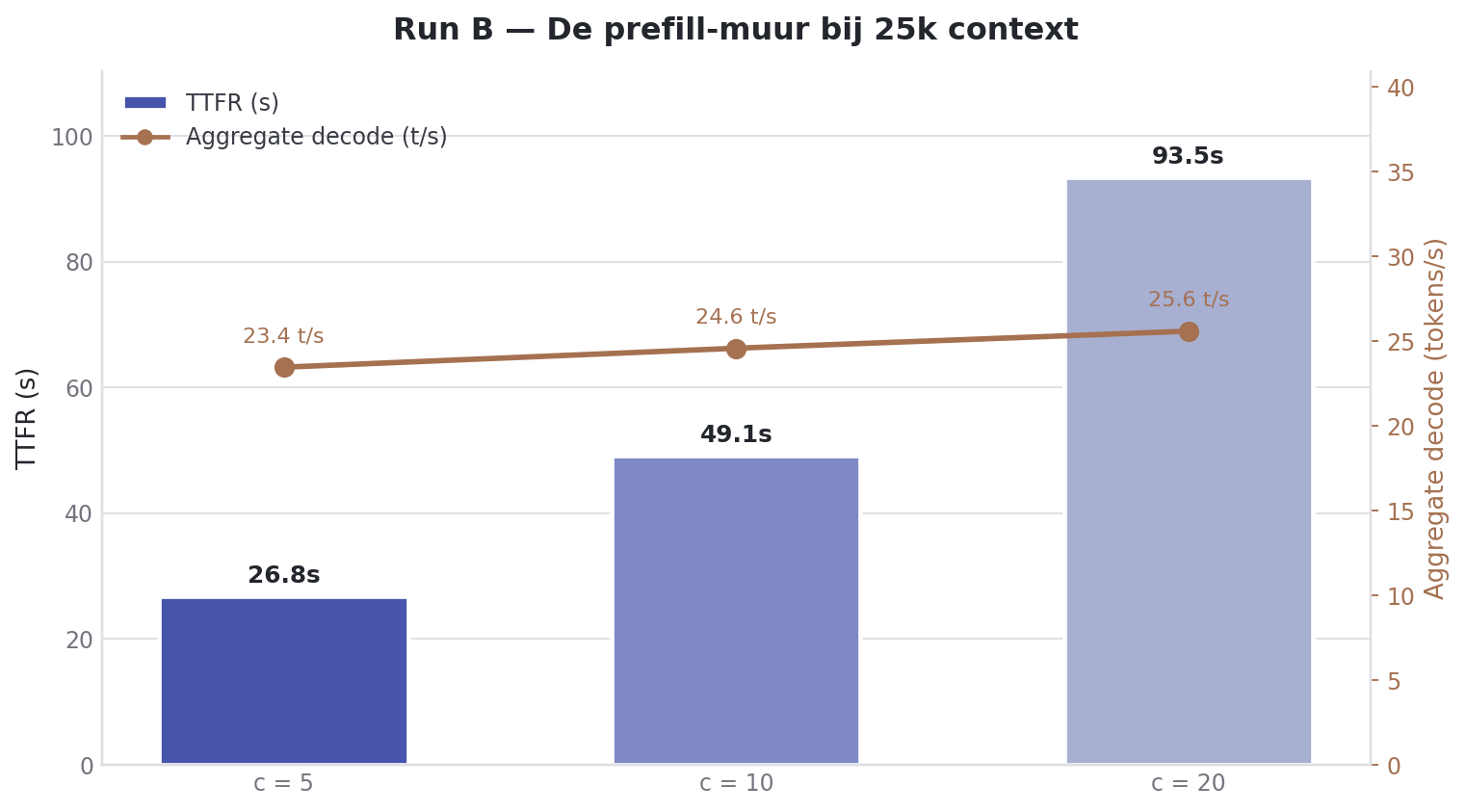
Dit is de stress-rand van de benchmark. Aggregate decode plakt rond 30 tok/s, ongeacht of je 5, 10 of 20 gebruikers neerzet. Per gebruiker zakt het van 8.51 naar 3.16 tok/s. Maar het echte probleem is TTFT: bij 20 gebruikers wacht de gemiddelde request 67 seconden voordat de eerste token komt. De server is dan niet stuk. De workload past alleen niet meer bij een realtime chatverwachting.
Run C: korte prompt, lange output
Run C draaide de vorm om. Niet 25k context met korte output, maar 1024 prompttokens en 1024 outputtokens.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 4627.12 ± 374.91 tok/s | 23.86 ± 0.03 tok/s | 23.86 ± 0.03 tok/s | 0.31 ± 0.02s |
| 5 | 5701.55 ± 561.36 tok/s | 13.59 ± 1.05 tok/s | 54.67 ± 4.90 tok/s | 0.76 ± 0.11s |
| 10 | 6346.87 ± 64.52 tok/s | 10.92 ± 0.73 tok/s | 86.46 ± 1.74 tok/s | 1.26 ± 0.40s |
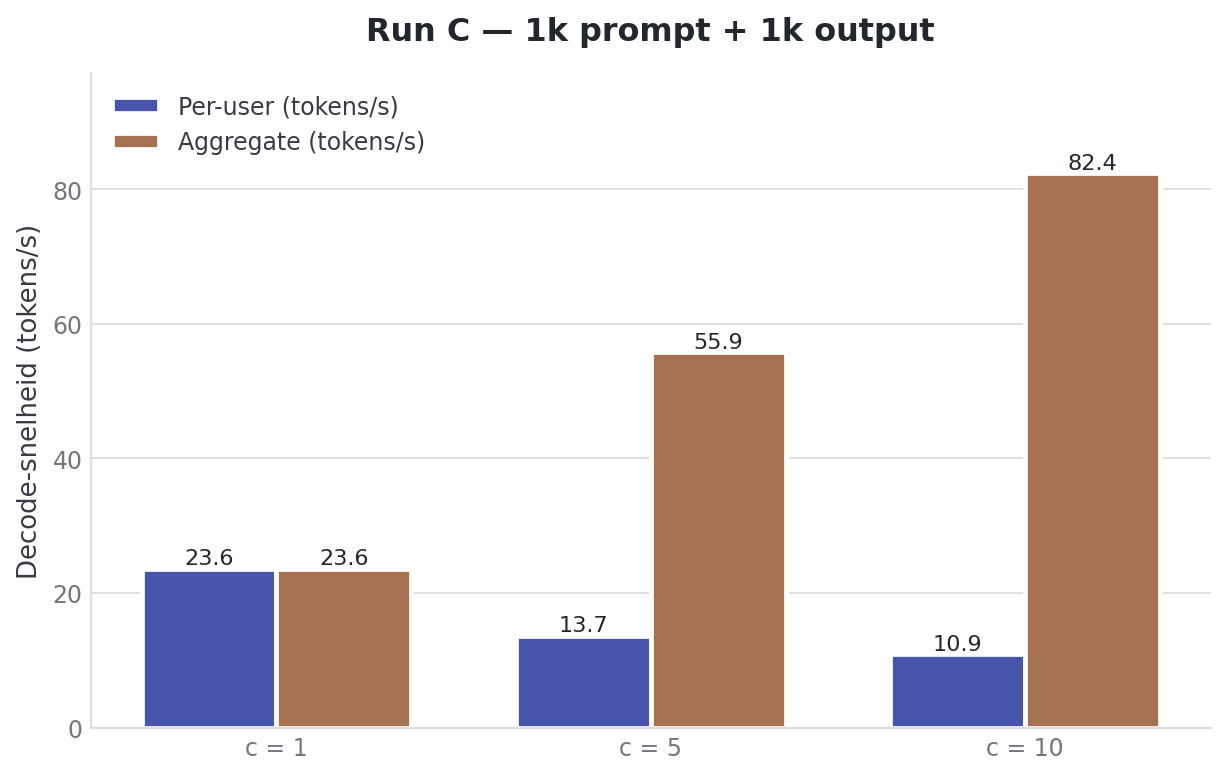
Bij tien gebruikers tegelijk blijft TTFT op 1.3 seconden. Dat voelt als chat.
Run G: nóg langere output
Run A, B en C lieten genoeg zien om het verhaal “decode is stabiel, prefill bepaalt de wachttijd” plausibel te maken. Maar er bleef één scenario open: wat als de output nog véél langer is? Een agent die code genereert. Een tool-call met gestructureerde output. Een lange samenvatting.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 1993.94 ± 262.05 tok/s | 24.17 ± 0.02 tok/s | 24.17 ± 0.02 tok/s | 0.24 ± 0.01s |
| 5 | 3048.28 ± 496.15 tok/s | 14.32 ± 2.18 tok/s | 46.11 ± 11.57 tok/s | 0.38 ± 0.07s |
| 10 | 4800.80 ± 50.75 tok/s | 11.75 ± 0.68 tok/s | 83.77 ± 4.04 tok/s | 0.48 ± 0.01s |
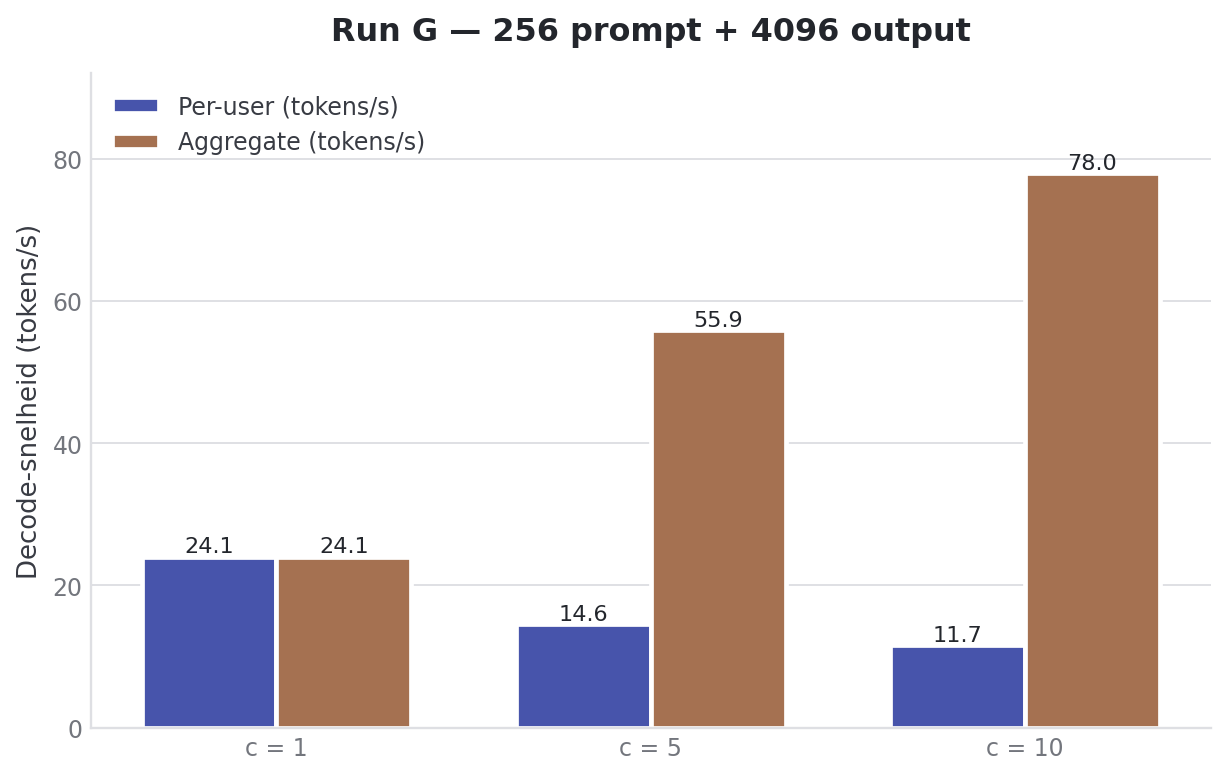
Decode/user over 4096 tokens zakt nauwelijks weg vergeleken met C’s 1024 tokens. Bij c=1 is het 24.17 (G) vs 23.86 (C). Bij c=10 is het 11.75 (G) vs 10.92 (C). Lange generaties compounderen niet, ze duren alleen proportioneel langer. En TTFT is hier het laagst: onder een halve seconde bij tien gebruikers tegelijk.
Run F: middelgrote context, meer gebruikers
Tussen Run C (1k context) en Run B (25k context) zat een gat dat dichter bij realiteit ligt. Een typische RAG-flow met vier chunks van ~2k tokens komt uit op zo’n 8k.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 5 | 5439.51 ± 32.60 tok/s | 12.11 ± 0.51 tok/s | 55.21 ± 1.49 tok/s | 4.32 ± 1.90s |
| 10 | 5466.71 ± 15.65 tok/s | 9.31 ± 0.77 tok/s | 78.36 ± 1.61 tok/s | 7.99 ± 4.02s |
| 20 | 5532.74 ± 5.39 tok/s | 6.05 ± 0.62 tok/s | 97.35 ± 3.50 tok/s | 14.61 ± 7.72s |
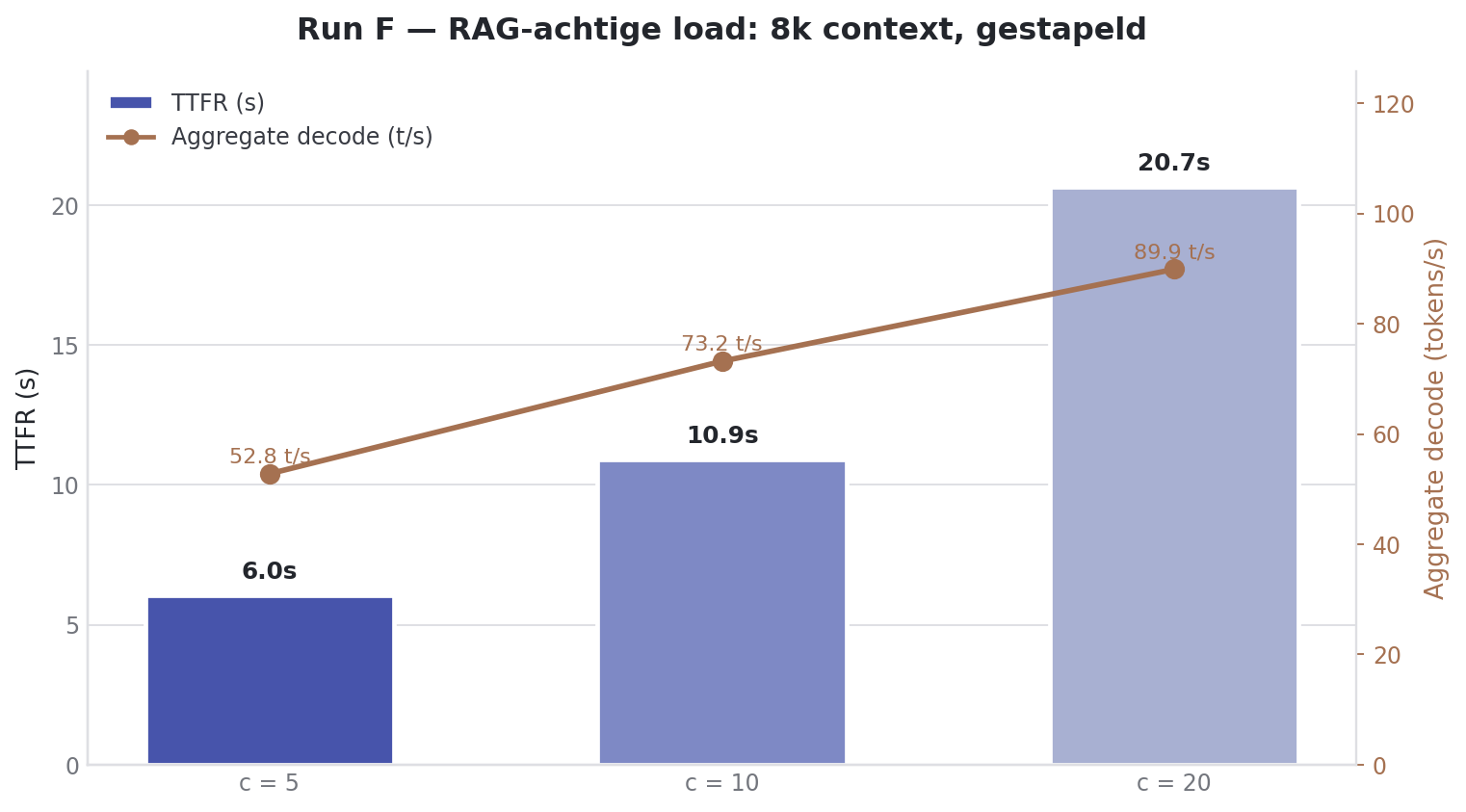
Drie observaties.
Prefill-throughput zit op een vlakke 5.5k tok/s, ongeacht of het 5, 10 of 20 gebruikers zijn. De machine is bij 8k context al gesatureerd op prefill-niveau. Aggregate decode blijft schalen: in Run B (25k) plateauerde dit op ~30 t/s, hier loopt het door tot 97.4 t/s. En het belangrijkste: TTFT bij 8k context is grofweg een kwart van wat het bij 25k is. Dezelfde concurrency, dezelfde machine, andere prompt-grootte.
Run E: multi-turn als realistisch kantoorwerk
--depth 4 betekent: per request vijf turns achter elkaar (initieel + vier vervolgvragen). Concurrency op 10 betekent: tien zulke gesprekken parallel.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 4716.21 ± 542.88 tok/s | 23.97 ± 0.10 tok/s | 23.97 ± 0.10 tok/s | 0.53 ± 0.06s |
| 5 | 5693.39 ± 128.08 tok/s | 13.07 ± 0.16 tok/s | 59.48 ± 2.26 tok/s | 1.32 ± 0.39s |
| 10 | 6096.81 ± 56.92 tok/s | 10.43 ± 0.35 tok/s | 92.42 ± 3.33 tok/s | 2.13 ± 0.83s |
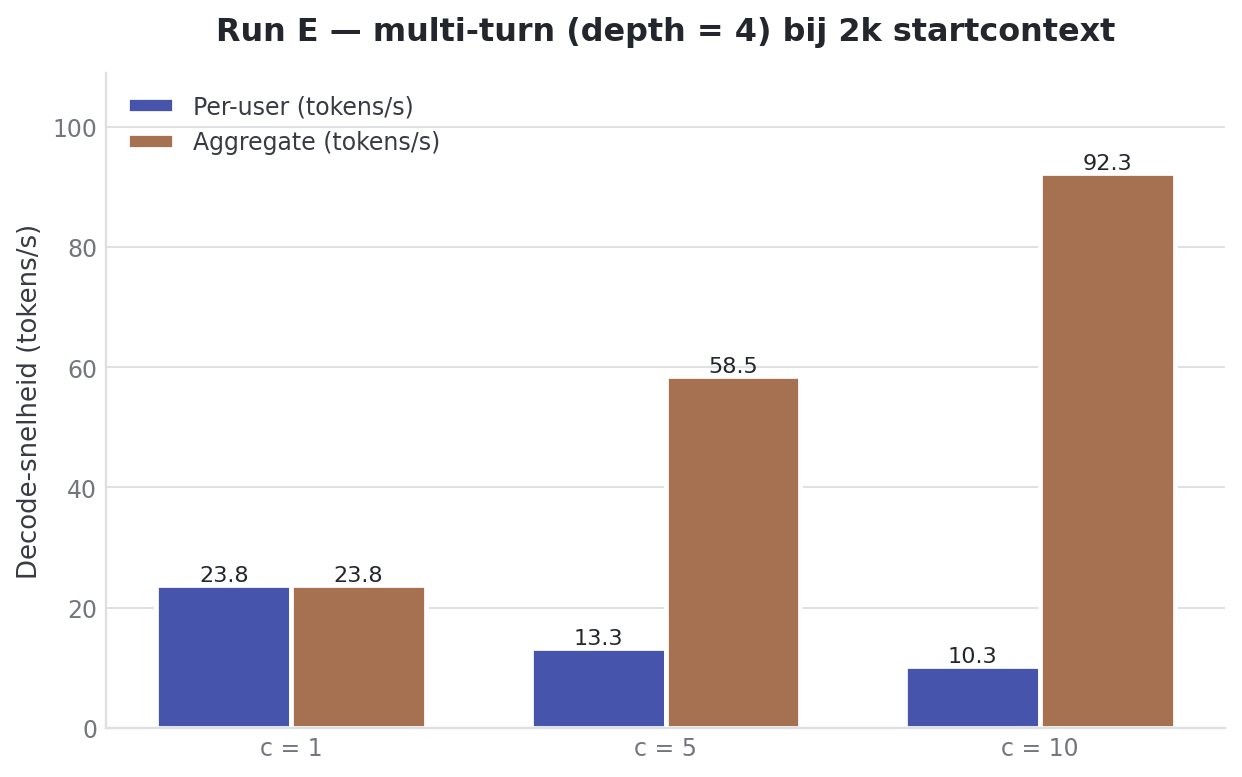
Drie dingen vielen op die ik vooraf niet had verwacht.
Per-user decode bij multi-turn is identiek aan single-turn. Multi-turn maakt de tokens niet langzamer, alleen het aantal prefills neemt toe. Aggregate decode op c=10 is 92.42 t/s, het hoogste van élke closed-loop run. vLLM krijgt bij multi-turn een dichtere stroom afhankelijke requests aangeleverd, en kan die efficiënter batchen dan tien losse single-shot prompts. En TTFT op c=10 is gemiddeld 2.13 seconden over alle vijf turns. Onder drie seconden voelt nog steeds als chat.
Wat de zes closed-loop runs samen laten zien
Eén tabel die alles bij c=10 naast elkaar zet:
| Run | Prompt | Output | Depth | TTFT (c=10) | Decode/user (c=10) | Aggregate decode (c=10) |
|---|---|---|---|---|---|---|
| G | 256 | 4096 | 0 | 0.48s | 11.75 t/s | 83.8 t/s |
| C | 1024 | 1024 | 0 | 1.26s | 10.92 t/s | 86.5 t/s |
| E | 2048 | 512 | 4 | 2.13s | 10.43 t/s | 92.4 t/s |
| F | 8192 | 512 | 0 | 7.99s | 9.31 t/s | 78.4 t/s |
| A | 16384 | 256 | 0 | 18.92s | 6.79 t/s | 45.8 t/s |
| A/B | 25000 | 256 | 0 | 35.67s | 5.40 t/s | 30.7 t/s |
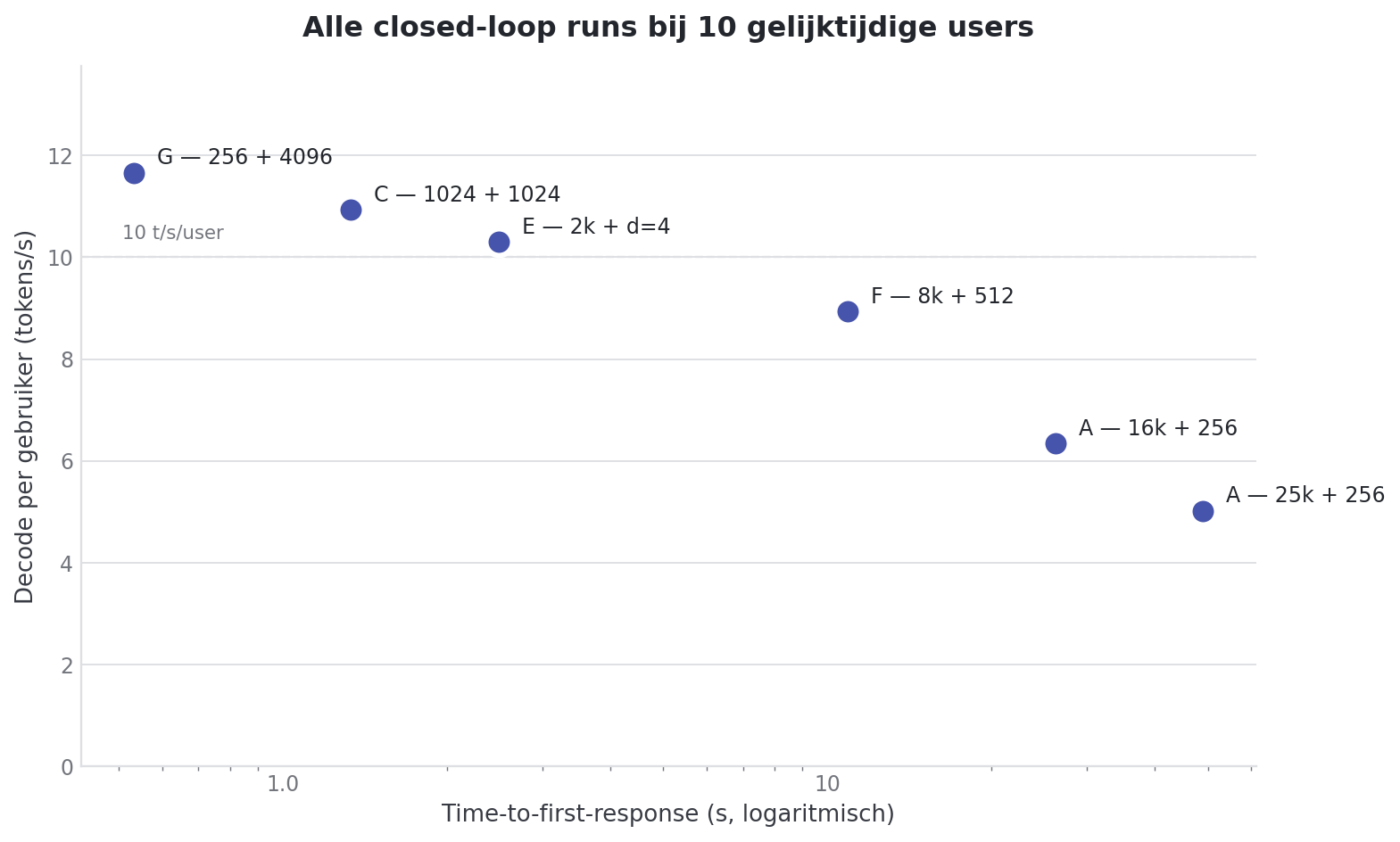
Twee patronen springen eruit.
Decode/user beweegt nauwelijks tot 8k context. Tussen Run G en Run F zit een factor 32 in prompt-grootte en een factor 8 in output-grootte. Toch zit decode/user daar tussen 9.3 en 11.8 tok/s. Pas bij 16k+ valt die strook in elkaar.
TTFT beweegt overal en is bijna een functie van prompt-grootte alleen. Verdubbel de prompt en de TTFT verdubbelt grofweg mee. Output-grootte en depth doen er voor TTFT bijna niets toe.
Dat is de closed-loop conclusie. Hij klopt, en hij vertelt een echt deel van het verhaal. Maar er zit een gat in.
Maar dit zijn synthetische tests
De zes runs hierboven testen capaciteit. Plafonds. Allemaal in dezelfde vorm: N gebruikers in lockstep, allemaal hetzelfde prompt-formaat, allemaal tegelijk verzendknopjes indrukkend. Dat is een prima manier om te meten waar het breekt. Het is een slechte manier om te meten hoe een echt kantoor voelt.
Want een echt kantoor heeft 25 medewerkers waarvan er gemiddeld een paar tegelijk wat doen. De ene collega vraagt een korte vraag. De andere is mid-RAG met 8k context. De derde zit in turn 4 van een gesprek. En verzoeken arriveren niet in lockstep. Ze arriveren als een Poisson-proces met af en toe een burst, omdat iemand net een mail af heeft en drie collega’s tegelijk aan koffie willen.
Dat is wat vLLM’s eigen vllm bench serve wel kan en llama-benchy niet:
- Open-loop met arrival rate. Verzoeken dispatchen volgens een Poisson- of Gamma-distributie, in plaats van lockstep.
- Percentielen. P50, P90, P95, P99 op TTFT, TPOT (time per output token), ITL (inter-token latency) en E2E. Geen mean ± stddev meer.
- Realistische datasets. ShareGPT replay van 94k+ echte gesprekken met natuurlijk variërende prompt-lengtes en multi-turn structuur.
- Mixed workloads. Prompts uit een distributie sampelen in plaats van één vaste shape testen.
Drie tests hieronder, dezelfde server (geen herstart), maar met die andere bril op.
Test H: realistische kantoor-baseline
Het scenario: 25 mensen actief gemiddeld, elk stuurt zo’n keer per 1–2 minuten een prompt, prompts variëren sterk in lengte. Aankomsten zijn licht clumpy.
docker exec vllm-bench vllm bench serve \
--backend openai-chat \
--base-url http://localhost:8000 \
--endpoint /v1/chat/completions \
--model google/gemma-4-26B-A4B-it \
--tokenizer google/gemma-4-26B-A4B-it \
--served-model-name gemma-4-26b-a4b-bf16 \
--dataset-name random \
--random-input-len 4000 \
--random-output-len 500 \
--random-range-ratio 0.9 \
--num-prompts 200 \
--request-rate 0.3 \
--burstiness 0.7 \
--percentile-metrics ttft,tpot,itl,e2el \
--metric-percentiles 50,90,95,99 \
--seed 42Met --random-range-ratio 0.9 variëren input-lengtes van 399 tot 7600 tokens, outputs van 49 tot 950. --burstiness 0.7 is iets clumpier dan pure Poisson. Mensen drukken vaak in burstjes op enter, niet als een metronoom. Target rate van 0.3 req/s = ~18 prompts/min over 25 gebruikers.
| Metric | Value |
|---|---|
| Successful requests | 200 / 200 |
| Achieved RPS | 0.27 (target 0.30) |
| Peak concurrent requests | 36 |
| Total token throughput | 1215 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 1395 | 1286 | 2284 | 2644 | 3316 |
| TPOT (ms) | 177 | 182 | 193 | 202 | 214 |
| E2E (ms) | 85921 | 85306 | 150192 | 162375 | 171351 |
Mediaan-gebruiker krijgt eerste token in 1.29s. Voelt nog als chat. De tail blijft binnen de perken: P99 wacht 3.3 seconden, ruim twee keer het gemiddelde.
En kijk naar peak concurrent: 36. Bij target rate van slechts 0.3 req/s. Geen enkele closed-loop run zat in die buurt. De Poisson-burstiness alleen al, gecombineerd met gemiddelde response-tijd van ~86 seconden, zorgt voor pieken die heftiger zijn dan welke Run B-stress-test ook had. Dat is het ding dat closed-loop letterlijk niet kan laten zien.
Test I: echte gesprekken (ShareGPT replay)
Identieke aankomst-pattern als Test H, maar nu met 250 echte multi-turn gesprekken uit ShareGPT V3 als prompts. Sommige zijn 1 turn van 200 tokens, andere zijn 15 turns met steeds groeiende context.
docker exec vllm-bench vllm bench serve \
... \
--dataset-name sharegpt \
--dataset-path /tmp/ShareGPT_V3.json \
--num-prompts 250 \
--request-rate 0.3 \
--burstiness 0.7| Metric | Value |
|---|---|
| Successful requests | 250 / 250 |
| Achieved RPS | 0.30 (target 0.30) |
| Peak concurrent requests | 17 |
| Total token throughput | 133 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 376 | 353 | 469 | 509 | 637 |
| TPOT (ms) | 93 | 95 | 117 | 123 | 135 |
| E2E (ms) | 19600 | 10923 | 49525 | 63036 | 82596 |
Dit is een ander universum dan Test H. TTFT P99 = 637 ms. 99% van de gebruikers ziet binnen 650 milliseconden de eerste token. Dat is écht chat-snelheid.
Identieke aankomst-pattern als Test H, totaal andere ervaring. Het verschil zit volledig in prompt-grootte: ShareGPT-gesprekken zijn gemiddeld 228 tokens, niet 4000. Korte prompt = goedkope prefill = geen queue-druk = sub-seconde TTFT.
| Metric | Test H (random 4k) | Test I (ShareGPT) |
|---|---|---|
| Achieved RPS | 0.27 | 0.30 |
| Peak concurrent | 36 | 17 |
| TTFT P50 | 1286 ms | 353 ms |
| TTFT P99 | 3316 ms | 637 ms |
| TPOT P50 | 182 ms | 95 ms |
Dit is ook een waarschuwing: de synthetische workload van Test H overdrijft hoe zwaar een gemiddeld kantoor-prompt is. Real-world conversations zijn lichter dan onze 4k random baseline, dus de praktijk-cijfers zitten vermoedelijk dichter bij Test I dan bij Test H.
Test J: maandagochtend-piek
Wat als iedereen tegelijk binnenkomt en op verzendknopjes drukt? Vijfvoudige load, max 25 gelijktijdige requests om een echt kantoor te modelleren.
docker exec vllm-bench vllm bench serve \
... \
--dataset-name random \
--random-input-len 4000 \
--random-output-len 500 \
--random-range-ratio 0.9 \
--num-prompts 300 \
--request-rate 1.5 \
--burstiness 1.0 \
--max-concurrency 25| Metric | Value |
|---|---|
| Successful requests | 300 / 300 |
| Configured RPS | 1.50 |
| Achieved RPS | 0.26 |
| Peak concurrent requests | 27 |
| Total token throughput | 1173 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 1370 | 1132 | 1932 | 2961 | 6157 |
| TPOT (ms) | 185 | 187 | 195 | 199 | 221 |
| E2E (ms) | 92752 | 91099 | 165179 | 172073 | 179139 |
Dit is het sleutelcijfer: achieved rate 0.26 bij target 1.5. Het systeem is bijna 6× throttled. Niet omdat ‘ie crasht (alle 300 requests slagen, geen failures), maar omdat de queue zich vult tot 25 en daar verzoeken vasthoudt totdat er ruimte is.
Vergelijk Test H (target 0.3) en Test J (target 1.5):
| Metric | Test H (0.3 rps) | Test J (1.5 rps) |
|---|---|---|
| Achieved RPS | 0.27 | 0.26 |
| TTFT P50 | 1286 ms | 1132 ms |
| TTFT P95 | 2644 ms | 2961 ms |
| TTFT P99 | 3316 ms | 6157 ms |
| TPOT P50 | 182 ms | 187 ms |
Mediaan-ervaring is bij Test J zelfs iets beter dan bij Test H (1.13s vs 1.29s). De cap zorgt voor een gelijkmatigere stroom. Maar de tail is dramatisch erger: P99 verdubbelt van 3.3s naar 6.2s.
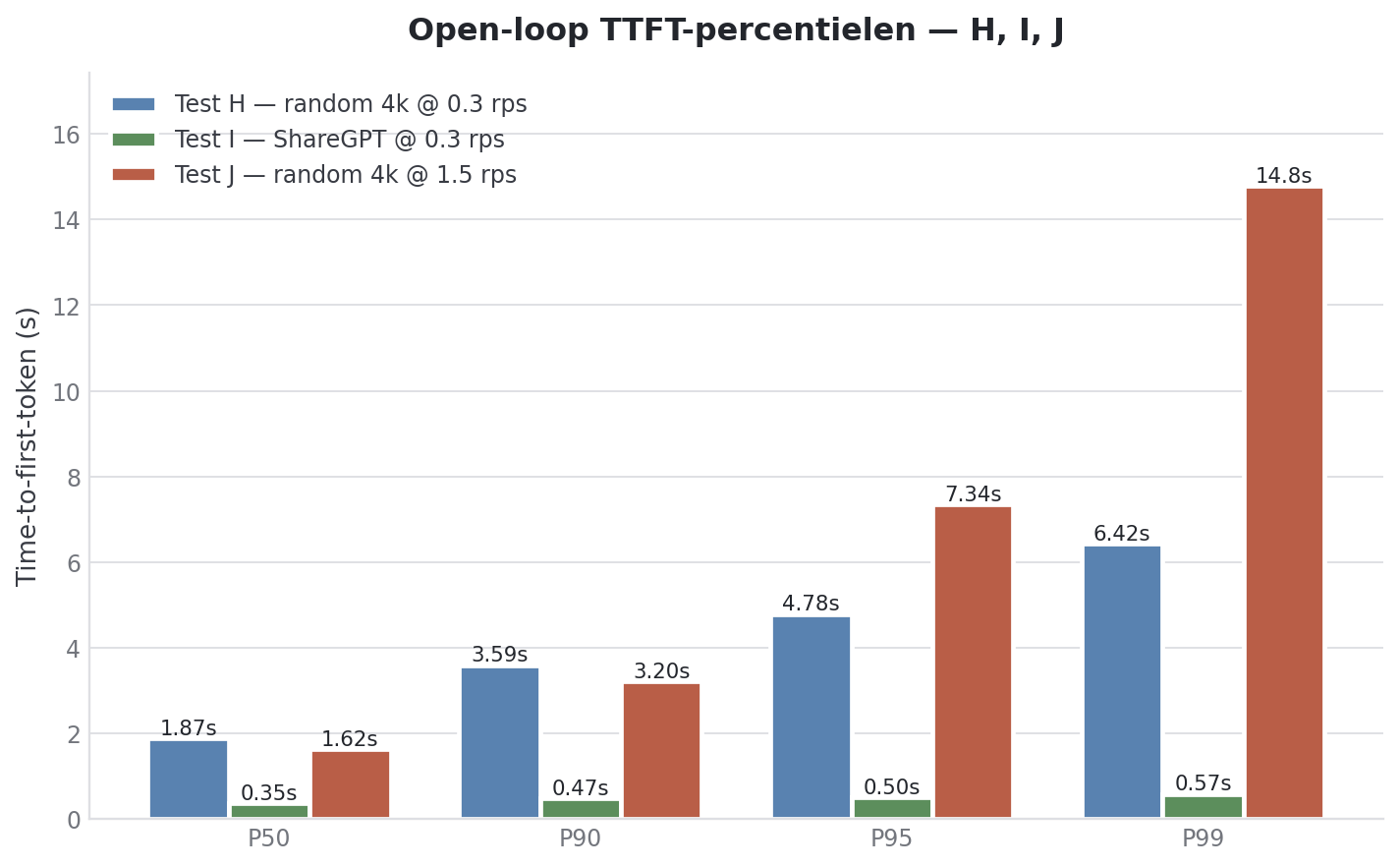
De Spark schaalt niet onder oversubscribe, hij queue’t. Dat is goed nieuws: graceful degradation in plaats van crashes. Voor on-prem AI is dat eigenlijk de beste failure-mode.
Wat closed-loop verbergt, wat open-loop overdrijft
De twee methodes vertellen elk een ander deel van het verhaal. Allebei waar, allebei onvolledig.
Closed-loop onderschat queue-diepte.
In Run F testte ik c=10 als “tien gebruikers tegelijk”. Dat klinkt als een redelijk drukke kantoorsituatie. Maar Test H toont dat een organische 0.3 req/s arrival rate al genoeg is om pieken van 36 gelijktijdige requests te produceren. De closed-loop “10 gebruikers” claim is dus optimistischer dan de praktijk laat zien.
Open-loop met synthetisch overdrijft de werkelijke load.
Tegelijk: Test H gebruikt random 4k-prompts. Een echt kantoor stelt geen 25 gemiddelde 4k-prompts per minuut. ShareGPT (Test I) is een veel betere proxy voor “wat mensen typen”, gemiddeld 228 tokens. Bij die workload-shape is peak concurrent 17 in plaats van 36, en P99 TTFT 637ms in plaats van 3.3s.
De praktijk zit dus tussen Run F en Test I in:
| Bron | TTFT (P50 of mean) | Peak concurrent |
|---|---|---|
| Run F (closed-loop, 10 users, 8k) | 7.99 s | 10 |
| Test H (open-loop, 0.3 rps, 4k random) | 1.29 s P50 / 3.3s P99 | 36 |
| Test I (open-loop, 0.3 rps, ShareGPT) | 0.35 s P50 / 0.64s P99 | 17 |
| Test J (open-loop, 1.5 rps, 4k random, cap 25) | 1.13 s P50 / 6.2s P99 | 27 |
Voor een kantoor met realistische prompts en realistische arrival pattern is Test I het dichtst bij wat mensen voelen. Voor capaciteitsplanning (“wat als iedereen tegelijk een 8k RAG-vraag stelt?”) is Run F het dichtst bij wat de machine kan verstouwen.
De tail vertelt wat het gemiddelde verbergt
llama-benchy gaf alleen mean ± stddev. Dat klinkt als veel informatie, maar het verbergt het deel dat er voor je gebruikers het meest toe doet: de tail.
Test I’s mean TTFT is 376ms. Klinkt prima. Maar wat zegt dat over de 1% gebruikers waar de queue net pikte? Niets. Daarvoor heb je P99 nodig, en die zit op 637ms. In dit geval geen probleem (allebei sub-seconde), maar het principe dat je moet kennen.
Test H’s mean TTFT is 1395ms. P99 is 3316ms. Ruim twee keer slechter dan het gemiddelde voor de unlucky 1%.
Test J’s mean TTFT is 1370ms. P99 is 6157ms. Ruim vier keer het gemiddelde.
Voor SLA-beslissingen (“ons systeem geeft binnen 3 seconden antwoord aan 95% van requests”) heb je deze percentielen nodig. Mean ± stddev kan een SLA suggereren die je niet haalt op de momenten dat het er het meest toe doet, namelijk wanneer er druk is.
Dat is waarom de blog niet alleen op llama-benchy kan landen. Capaciteit testen is één ding. Tail-latency rapporteren is een ander.
Decode is het probleem niet
Bij één gebruiker blijft decode bijna vlak.
4k context haalt 24.08 tok/s per gebruiker. 25k context haalt 22.75 tok/s. 4096 outputtokens (Run G, c=1) haalt 24.17 tok/s. Multi-turn met depth 4 (Run E, c=1) haalt 23.97 tok/s. Vier verschillende workloads, allemaal binnen 6 procent van elkaar.
Bij tien gebruikers tegelijk gebeurt iets vergelijkbaars, alleen op een lagere lijn. Run G: 11.75 tok/s/user. Run C: 10.92. Run E: 10.43. Run F: 9.31. En in de open-loop tests: Test I geeft TPOT P50 = 95ms = ~10.5 tok/s/user. Test H en J geven TPOT P50 = ~185ms = ~5.4 tok/s/user (omdat pieken daar 25+ concurrent halen).
Kortom: per-token decode-snelheid is een functie van gemiddelde concurrent load, niet van prompt-lengte, output-lengte, multi-turn, of arrival pattern. Pas bij 16k+ context gecombineerd met meerdere users (Run A) zakt het echt door 7 t/s/user.
Concurrency op zichzelf is niet het probleem. Lange output ook niet. Multi-turn ook niet. Pas grote context tegelijk met meerdere gebruikers eet decode op.
Prefill is de muur
Wat je als eerste voelt, is wachten.
Bij één gebruiker op 25k context duurt het ruim 6 seconden voordat de eerste response komt. Bij vijf gebruikers wordt dat 19.9 seconden. Bij tien wordt het 35.4 seconden. Bij twintig wordt het 67.4 seconden.
Run F laat zien dat dit lineair is in zowel concurrency als context. 8k context bij 20 gebruikers geeft 14.6 seconden, ongeveer een kwart van de 67.4 seconden bij 25k context, voor dezelfde concurrency. Halveer de prompt, halveer de wachttijd.
En Test J laat zien: zodra je het systeem voorbij zijn doorvoer-plafond pusht, gaat al die extra wachttijd in de tail zitten. Mediaan TTFT blijft stabiel rond 1.1-1.3s, maar P99 schiet naar 6 seconden. De pijn van overbelasting valt op een kleine groep, niet op iedereen.
Daar zit de echte grens.
Niet: kan de DGX Spark tokens genereren? Ja.
Niet: kan de KV-cache 20 × 25k aan? Ook ja.
Niet: stopt het bij overload? Nee, het queue’t netjes door.
Maar: voelt dit nog als chat? Niet voor 25k. Voor 8k al wel grensgebied. Voor 2k met multi-turn gewoon prima. Voor ShareGPT-realistische prompts met 25 gebruikers organisch verspreid: glashelder ja.
Waar dit wel past
Deze benchmarks maken de on-prem keuze concreter.
Ja voor een kantooromgeving waar 10 tot 25 mensen verspreid over de dag lokale AI gebruiken. Test I is het bewijs: 250 echte ShareGPT-gesprekken, 0.3 req/s aankomst-rate, P99 TTFT van 637ms. Mediaan-gebruiker ziet de eerste token in 353 milliseconden. Dat is precies het kantoor-scenario, en dit is wat het voelt.
Ja voor RAG-flows met middelgrote context. Run F gaf de cijfers vooraf: 8k prompt, 10 users, 8s TTFT, 9.3 tok/s streamen. Test H bevestigt dat de open-loop variant nog steeds werkbaar is: P99 TTFT 3.3s. Niet realtime, wel binnen wachtbare grenzen.
Ja voor agents en code-generatie. Run G is de bevestiging: korte instructie, 4k+ tokens output, tien parallelle taken. TTFT onder een halve seconde, 11.75 tok/s/user.
Ja voor multi-turn gesprekken. Run E geeft 2.1s TTFT bij 10 parallelle 5-turn gesprekken. Decode hetzelfde als single-turn.
Voorzichtig bij 5+ gebruikers met 25k context tegelijk. 19.9 seconden TTFT is geen chat meer, wel werkbaar voor analyses.
Voorzichtig met SLA-claims op basis van gemiddeldes. Test H’s mean TTFT van 1.4s zou als acceptabel kunnen klinken, maar P99 zit op 3.3s. Beslissingen op basis van percentielen, niet op mean.
Nee voor support-chat waarbij tien tot twintig gebruikers tegelijk 25k context per sessie sturen en allemaal realtime antwoord verwachten. Of: support-chat onder Test J-achtige load (1.5 rps van 4k-prompts). Dat kan technisch draaien (geen failures), maar P99 TTFT van 6 seconden is een grensgeval voor chat.
Wat deze tests niet zeggen
Dit is geen MoE-vs-dense vergelijking. Dat wil ik apart testen, en dan niet alleen met throughput. Als je MoE en dense vergelijkt, moet je ook prompts testen: samenvatten, codevragen, tool-keuze, ticket-classificatie, lang contextstuk met vervolgstappen. Anders meet je alleen hoe hard de motor draait, niet of hij de goede kant op rijdt.
Dit is ook geen test met prefix caching aan. Dat is bewust. Ik wilde de rauwe prefill-kosten zien, niet een benchmark die mooier wordt omdat prompts op elkaar lijken. In een volgend stuk gaat dat erbij: diezelfde 8k en 25k context-runs en de open-loop tests met --enable-prefix-caching. Mijn vermoeden: Test H en J profiteren matig (random data, weinig overlap), Test I profiteert behoorlijk (echte gesprekken hebben overlappende system prompts en context), en Run F gaat substantieel sneller. Maar dat moet gemeten worden.
Waar ik land
Mijn verwachting vooraf was dat de DGX Spark met dit MoE-model eerder zou vollopen bij grote context windows. Dat gebeurde, maar anders dan ik dacht.
Geheugen was niet de showstopper. Run B haalde 20 gebruikers met 25k context zonder OOM. Test J overleefde 1.5 req/s zonder een enkele failed request. De praktische grens zat altijd in prefill-latency, niet in capaciteit.
En na negen tests blijkt: dat is eigenlijk de enige grens die je voelt.
Decode/user is bijna een constante voor deze machine. Tussen 9 en 12 tokens per seconde bij tien gelijktijdige gebruikers, in zes verschillende closed-loop workloads. In open-loop met realistische ShareGPT-prompts: 10.5 t/s/user. Pas bij 16k context of bij synthetische pieken van 25+ concurrent valt dat onder de 7 t/s.
Wat varieert is hoe lang iemand wacht voordat de tekst begint. Op 256 prompttokens is dat een halve seconde, ook met tien gebruikers. Op 2048 prompttokens met vijf turns gemiddeld 2.1 seconden. Op 8192 prompttokens met tien gebruikers acht seconden. Op 25k met tien gebruikers 35 seconden. Op realistische 0.3 rps ShareGPT-belasting: 353 milliseconden voor de mediaan, 637 milliseconden voor de unlucky 1%.
En zodra je het systeem boven zijn capaciteit duwt, schaalt ‘ie niet, hij queue’t. Test J liet zien dat 1.5 req/s target wordt gethrottled tot 0.26 achieved, met de pijn volledig in de tail (P99 6.2s) terwijl de mediaan stabiel blijft. Voor on-prem AI is dat de beste failure-mode die je kunt hopen: niemand crasht, sommigen wachten langer.
Dat is geen “kan deze machine het wel of niet”. Dat is “kies de workload die past bij wat de gebruiker verwacht, en accepteer dat 1% van de requests een onaangename wachttijd heeft op piekmomenten”.
Voor één tot drie gebruikers met grote context is hij bruikbaar. Voor tien gebruikers met middelgrote context is hij prima. Voor tien gebruikers met multi-turn gesprekken is hij eigenlijk op zijn best. Voor een 25-persoons-kantoor met realistische prompts en organische arrival pattern is hij verbluffend goed: sub-seconde TTFT voor 99% van requests, gemeten op echte conversation-data.
Voor agent-flows met lange outputs is hij sterk. Voor twintig gelijktijdige 25k-prompts of voor 1.5 rps oversubscribe is het geen realtime chat meer. Daar moet je queue’en, prefix caching aanzetten, of dat type werk anders routeren.
Twee methodes meten twee dingen. Closed-loop benchmarks tonen wat de machine kán. Open-loop replay toont wat de gebruiker voelt. De DGX Spark is een sterke lokale AI-machine voor kantoorwerk, zolang je weet welke knop bepaalt wat je voelt.
Decode verkoopt de benchmark. Prefill bepaalt de ervaring. En zodra je de plank voorbij gaat, queue’t de Spark in plaats van te breken, en dat is het derde cijfer dat een on-prem-keuze moet kunnen lezen.